はてなようせいとまなぶ Schemeの形式的意味論
~かっこわるいSchcmerへの道~

わからない……
わからない……
R6RSの
Appendix Aに載っている形式的意味論がわからない……

Schemeの形式的意味論を理解するための冒険は、
R6RSを印刷して読みながら、実際にPrologとかで、
意味論にそったインタプリタを作ることよ
わからない……
そんな面倒なことをする意味があるのかわからない……
本当にそれで理解できたのかは筆者もわからない……
それじゃあ、簡単に説明をするからよく聞いてね。
けど、それでもR6RSを印刷したほうがいいわ。
それから、R6RSは「みんなもってる」ものなので、
自分のものだと分かるように、ちゃんと名前を書かないとだめよ。
「おなまえシール」を貼るというのも手ね。
もくじ

- なにをするの
- おおざっぱに
- もうすこしせいかくに
- きほん
- かきかえ
- むずかしいかきかえ
- ぶんぽう
- やくそくときほん
- ぷろぐらむのぶんぽう
- ぶんみゃくとあな
- ぶんみゃくのぶんぽう
- くぉーと
- かんやくきそく
- くみこみかんすう
- たち
- かんやくきそく
- れいがい
- めんどうなんでしょうりゃく
- すうちけいさん
- かんやくきそく
- きほんふぉーむ
- かんやくきそく
- りすと
- かんやくきそく
- てつづきとてきよう
- かんやくきそく
- くみこみかんけい
- こーるしーしーとだいなみっくうぃんど
- かんやくきそく
- くみこみかんすう
- れっとれっくとか
- めんどうなんでしょうりゃく
- おわりに
- かんたんないみろんをうつしてそくいんたぷりた
内容が完成してから目次を書いてみたら、
驚くほど大作になってたことに筆者はおったまげたそうよ。
なにをするの
R6RSは印刷できた?
ちゃんと名前も書いた?
それじゃあ私の言うことをちゃんと聞いてね♪
おおざっぱに
なにをするのかというと、Schemeのプログラムを入力として受け取って、
それを評価した結果を返す抽象機械(abstract machine)の振る舞いを定めます。
もうすこしせいかくに
より正確に言うと、プログラムの集合Pから表示可能な結果の集合Rのべき集合2
Rへの関数Sを定義します
(†1)。
抽象機械の1回の動作(単一ステップ簡約 : single-step reduction)で状態がXからYに遷移することを X→Y と表し、
単一ステップ簡約を繰り返し(抽象機械が動作を繰り返し)、状態がXからZに遷移することを X→
*Zと表します。
正確には関係→
*は関係→の遷移的閉包(transitive closure)ですが、そんな面倒な話はやめておきましょう。
きほん
抽象機械の振る舞いの定義の仕方を見てみましょう。
普通のインタプリタは決まった規則で順番に部分式を評価するけど、
抽象機械はてきとーに簡約できそうな場所を簡約するのよ。
いい加減な性格なのね♪
(簡約っていうのは単純な形にすることよ)
かきかえ
単一ステップ簡約の基本方針は「書き換えてよさそうな箇所
(*1)があったら書き換える」というものです。
例えば、式の中に
(+)
という部分式があり、これが書き換えていい箇所なら、これを0に書き換えます
(*2)。
この規則は次のように定められています。
P1[(+)] → P1[0]
ここでのPは「評価文脈」(evaluation context)と呼ばれるものです。
評価文脈は「式の次に評価すべき部分式を文脈の穴(hole)によって示した文脈」などと説明できますが、
これではいまいち意味がわかりませんね。
まあ、詳しい説明はあとでしましょう。
(*1)例えば (begin (+) (+ 1 2)) の (+) は書き換えていい箇所ですが、 (+ 1 2) は書き換えてはいけない箇所です。
(*2)Schemeにおいて (+) の値は 0 となっています。
むずかしいかきかえ
もう一つ、評価文脈の例を見てみましょう。
これはR6RSに載っているものです。
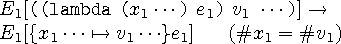
この「...」はクリーネ閉包(Kleene star)、つまり0回以上の繰り返しを表します。
この場合は、xが0個以上並び、vも0個以上並ぶということを示しています。
#x
1はxの並ぶ個数、#v
1はvの並ぶ個数です。
カッコつきで右に書いてあるのは、この条件が満たされないとこの規則は使えないことを表しています。
{x1… |-> v1…}e1
これはeに現れる1つ目のxを1つ目のvで、2つ目のxを2つ目のvで、といった風に置き換えたものを表します。
ちなみにこの規則は関数呼び出し(β簡約)を表しています。
(#x
1 = #v
1) がついているため、
実引数と仮引数の数が等しいときのみ使えます。
ぶんぽう
いよいよ本格的な内容になってくるわ。
いきなり沢山のことが出てきて大変かもしれないけど、
私が応援してるからね♪
やくそくときほん
まず、プログラムの文法を定めましょう。
ここでは非終端記号(non-terminal)は通常のフォント、終端記号は
太字で表すことにします。
また、非終端記号を使うときは e
1 のように添え字を下に付けることがあります。
すると、プログラムの状態は基本的に次の形式で表されます。
(store (sf ...) es)
sfはメモリの内容を示す非終端記号です。
例えば、変数varに3が入っている場合sfは (var 3) のようになるといった感じです。
esはクォートを許す式を表す非終端記号です。つまり、任意の式と考えればいいです。
ぷろぐらむのぶんぽう
これを念頭においてR6RSの完全な文法の定義を眺めてみましょう。
Pはプログラムを表す非終端記号、Aは結果を表す非終端記号、
Rは結果を表示可能な形式にしたものを表す非終端記号です。

これを見る上で注意することは sym と 'sym の違いです。
この sym は非終端記号ですが、
' は終端記号です。
正直分かりにくいので (
quote sym) と考えた方がいいでしょう。
'sqv, '()なども同様です(ただし、
()は終端記号)。
また、eはクォートを含まない式を表す非終端記号ですが、 'sym は例外的に含みます。
これはクォートがないと x と sym の見分けが付かなくなるためかと思います。
dotはその名の通り「
.」を表します。
[immutable pair pointers]と[immutable pair pointers]はユニークな記号の集合です。
適当に眺めたらあとは、必要になったときに見返せばいいでしょう。
ぶんみゃくとあな
評価文脈とは「式の次に評価すべき部分式を文脈の穴によって示した文脈」と説明しましたが、
言い方を変えると「穴の開いた不完全な式」です。
(begin e0 e1 e2 ...)
これは式です。そういっても誰も文句を言わないでしょう。
では、次のものはどうでしょうか(等号の右辺に注目してください)。
F1 = (begin [] e1 e2 ...)
前者とほぼ同じですが、一箇所だけ 穴[] があいています。
この一箇所だけ穴の開いた式を評価文脈といいます。
文脈F
1の穴に e
0 を入れると前者と同じ式になりますね。
これを F
1[e
0]のように表します。
穴の中には任意のものを入れることができます。
ぶんみゃくのぶんぽう
R6RSの完全な文脈の文法の定義を眺めてみましょう。
文脈Pは一箇所だけ穴の開いたプログラムを表し、
文脈E, Fは一箇所だけ穴の開いた式を表します。
これらは正しい評価順序が得られるように穴の位置が決められれていまスが、
文脈Sはクォートを外すのに使用するためあらゆるところに穴がくることができます。
こういった話は最初はよく分からなくても後述する簡約規則(reduction rule)を
読んでいるうちに分かるでしょう。

例えば、Fは次のような形を取ることができます。
(begin (set! x [])
e)
また、[]
*と[]
oといったものが現れますが、これは通常の穴[]とは異なります。
これらの穴は P[(values v ...)]
* や P[v]
o といった風に、
文脈に明示的に指定したときのみ使用します。
逆に、それらが指定された場合は通常の穴[]は使用しません。
穴[]
*は多値(multiple values)が望まれる場所で使用され、
穴[]
oは単一値(single value)が望まれる場所で使用されます。
E ::= F[(handlers proc ... E*)]
のようなものの意味は
「文脈Fの穴に (handlers proc ... E
*) を入れることが可能で、実際の穴はE
*にある」
ことを意味します
(†2)。
(begin (handlers proc
(handlers [] ))
e)
などがその条件に適合します。
穴というものが分かりにくければ、ただの[], []
*, []
oという三種類の終端記号と考えればいいでしょう。
そう考えると、穴に何か入れるというのは、特定の終端記号を別のもので置き換えるというだけです。
くぉーと
前に文脈Sという定義の長いものを見たと思うけど、
それを使ってquoteの簡約を行うわ。
ちなみに文脈Sが出てくるのはここだけよ。
あんなに定義が長いのに悲しくなるわね……
かんやくきそく
簡約規則というものを見てみましょう。
簡約規則とはそのまま「簡約の規則」です。
つまり、抽象機械の一回の動作を規定するわけです。
ここで登場するのはクォートを外す規則です。
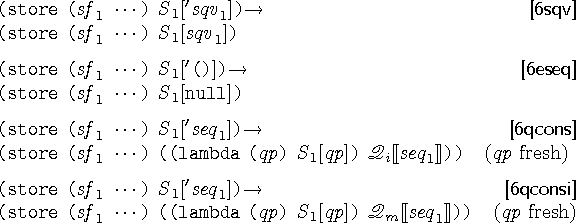
上から順に見ていきましょう。
sqvは自己クォートな値(self-quoting value)、つまり評価したら自分自身になる値です。
1番目の規則はこの自己クォートな値にクォートが付いていたら外せることを定義しています。
(store () (begin '551 '#t '171))
このようなプログラムにこの規則を使うことを考えて見ましょう。
文脈Sの生成規則から(begin [] es es)という文脈が作れることができ、これをS
1とします。
すると上記規則が使用でき、
(store () S1['551]) →
(store () S1[551])
となり、結果は (store () (begin 551 '#t '171)) となります。
同様に文脈Sから(begin e [] es)という文脈を作れることにより、
第2引数、第3引数のクォートも外せます。
ちなみに、eはクォートの付いていない式、esはクォートを含む式なので、
文脈Sの文法から、クォートはかならずbeginの左から外れていくのが分かります。
次に、2番目の規則を見てみましょう。
これは入力'()を空リストを表す終端記号
nullに変えるだけです。
3番目と4番目の規則を見てください。 → の左辺が全く同じ形をしています。
これはどちらか好きな方を(処理系の実装者が)選んでいいことを示しています。
これらの規則はリストに対するクォートの処理です。
また、 (qp fresh) とは、qpという識別子がユニークなもの(gensymで生成されるようなもの)
であることを示しています。
くみこみかんすう
ここで L
i[[X]] と L
m[[X]] といった記号が登場していますが、
これは組み込み関数で、以下のように定義されています。

一言で説明すると、リストをconsを使った式に直します。
L
iは通常のconsを使い、書き換え可能(mutable)なリストを作っています。
L
mはconsiというものを使い、書き換え不可能(immutable)なリストを作っています。
なんかこの組み込み関数、iとmが逆な気がするんですが、そう定義されてるんで仕方ないですね。
間違えやすそうなのが
Li[[sym1]] = 'sym1
です。クォートをつけないと変数と間違えられて評価されてしまうため、このようになっています。
ちなみに、 F['sym]→F[sym] のような規則は存在しないため、
シンボルのクォートは最後まで取れることはありません。
(これは普通のインタプリタの実装とは大きく違いますね)
たち
この節は説明が短くて読みやすい気がするけど、
それは説明をしてないからよ♪
たちが悪いわね。
call-with-valuesの定義は頑張って自分で読んでね。
かんやくきそく
次に、多値に関する簡約規則を見てみましょう。

1つ目の規則を見てみましょう。
穴[]
*を使用しています。
これは、多値が望まれているところに単一値がある場合、多値に書き換えます。
(store () (begin 6))
→(store () (begin (values 6)))
といった感じです。
2番目の規則はその逆で、単一値が望まれているところに、
一つだけ値を持つ多値がある場合に書き換えます。
(store () (if (values #t) 1 2))
→(store () (if #t 1 2))
3つ目、4つ目はcall-with-valueに関する規則です。
これについては説明しなくても大丈夫でしょう。
れいがい
R6RSはそこらじゅうでexceptionをraiseしなさいってうるさいの。
でもその割には例外の扱いが
「Standard Libraries」の方にしか載ってないの。
いい加減よね♪
めんどうなんでしょうりゃく
はてなようせいさんが言って下さった通り、
R6RSの本編(?)には例外の扱いが載ってないので説明は省略します。
面倒だったからじゃないですよ!
すうちけいさん
このあたりから説明がかなりいい加減になってきてるわ
この説明に頼らずに頑張って自分でR6RSを読んでね♪
あと、早速例外の説明を省略した付けが回ってきたわ。
"raise"とかは気にしちゃだめよ♪
かんやくきそく
数値計算に関する簡約規則を見てみましょう。

例えば、
(store () (begin (+ 1 2) (* 3 4)))
というプログラムを簡約する場合を考えて見ます。
文脈Pの生成規則から (store () (begin [] e)) という文脈を作ることができ、
この穴に (+ 1 2) を入れることで、規則が適用でき、
(store () (begin 3 (* 3 4)))
に簡約されます。
そして、多値に関する規則を適用することにより(穴[]
*に3を入れる)
(store () (begin (values 3) (* 3 4)))
に簡約することができます。
ただし、現状の規則ではこれ以上簡約できません。
というのも、Fの生成規則を見れば分かるように、beginの第2引数の位置に穴はこれないからです。
逆に言えば、beginは必ず第1引数が評価されることが保障されています。
beginが引数を左から順番に評価して、
最後の式を全体の結果とするにはbeginの簡約規則を定める必要があります。
きほんふぉーむ
beginやifの規則をつくるわ。
これができたらずいぶん面白くなってくるわよ。
あと、begin0は引数を左から順番に評価していって、
最後に第1引数を結果として返すものよ。
よくよく見てみたらどこでも説明してなかったから今言うわね♪
かんやくきそく
基本的なフォームに関する簡約規則を見てみましょう。
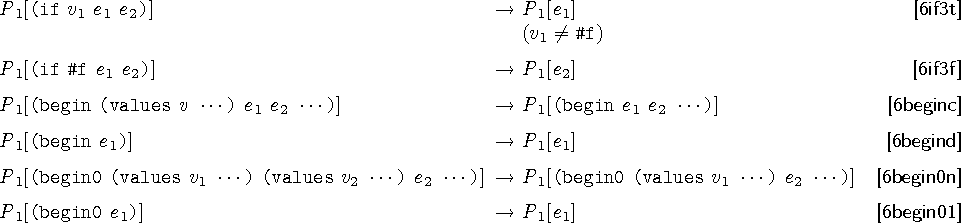
さっき、途中まで簡約したbeginの例の続きを考えて見ましょう。
(store () (begin (values 3) (* 3 4)))
文脈Pの生成規則から (store () [] ) という文脈を作ることができ、
この穴に (begin (values 3) (* 3 4)) を入れることにより、規則を適用し、
(store () (begin (* 3 4)))
に簡約することができます。簡約を繰り返すことにより、最終的には
(store () (values 12))
となります。これはプログラムの最終結果となります。
次に、ifに関する規則を見てみます。
文脈Fの生成規則から (if [] e
1 e
2) という文脈を作ることができるため、
ifの条件部は通常通り、簡約することができます。
ただし、ifの規則を使わなければe
1, e
2は評価されません。
条件部の簡約が終わり、値(v)になればifの規則を用い、
if文全体がe
1かe
2のどちらかに簡約されます。
りすと
コンスセルをつくるために、メモリというかヒープを使うわ。
でもR6RSの中ではstoreって呼んでるから注意してね。
もはや説明が完全に投げやりだから頑張ってね♪
かんやくきそく
リストに関する簡約規則を見てみましょう。
ここで今まで使っていなかった (store (sf ...) e) のsfを使用します。

最初の2つの規則は関数listをconsに書き換えるものです。
次の規則はconsに関する規則です。
consを適用すると、メモリ上にコンスセルが作られます。
そして、それにはmpというアドレス
(*3)が割り振られ、
簡約結果はそのアドレスとなります。 (mp fresh) とあるため、
コンスセルは常に新しいアドレスに割り当てられることになります。
carとcdrはメモリから引数に指定されたアドレスを探し、そのCAR/CDRを返します。
また、set-car!, set-cdr!はメモリ上のコンスセルの値を書き換えます。
下に例を示します。
(store () (car (cons 5 6)))
→(store ((mp1 (cons 5 6))) (car mp1))
→(store ((mp1 (cons 5 6))) 5)
→(store ((mp1 (cons 5 6))) (values 5))
(*3)R6RSではアドレスという表現は使われていません。
でもこれがいちばんしっくりとくるので、使いました。
てつづきとてきよう
仮引数を直接値で置き換えるようなことをしてるから、
(lambda (x) (lambda (x) x))
なんて式があったらまずいんじゃないかと思ったら、
"capture-avoiding substitution"
の一言でR6RSは済ませてるわ。セコいわね。
かんやくきそく
手続きに関する簡約規則を見てみましょう。
引数の評価順序は決まっていないため、すこし変な感じの規則となっています。

1つ目の規則はlambdaを使って引数の評価を1つずつに分解しています。
v ⊂ e であることに注意してください。
文脈Fの評価規則を見直してみてください。
F ::= (v ... Fo v ...)
手続き呼び出しに利用する文脈ですが、穴を作ることのできるF
oの箇所を除き、
全てv(簡約済みの値)となっています。
((lambda (x) e
1) e
2)
とすると、lambda式はvであるため、文脈 (v []) の穴にe
2を入れることにより、
引数を評価することができます。
逆に言えば、 (e
1 ... e
i e
i+1 ...) に1つしか、
e(not v)が含まれていない場合、eは上記文脈を使って簡約できるため、
この規則を使う必要がありません。
よって、1つ目の規則は複雑な条件付きとなっています。
例を示します。
(store () (cons (+ 1 2) (* 3 4)))
→(store () ((lambda (x1) (cons x1 (* 3 4))) (+ 1 2)))
→(store () ((lambda (x1) (cons x1 (* 3 4))) 3))
2つ目、3つ目の規則は手続きの適用に関する規則です。
3つ目の規則は仮引数を実引数で置き換えます。
2つ目の規則は手続きに引数に対するset!が含まれる場合のみに使われます。
これは、実引数の値をメモリにコピーし、そのアドレスで変数を置き換えます。
4つ目の規則は全引数に対する処理が終わった後にlambdaをbeginに書き換えます。
(store () ((lambda (x1) (cons x1 (* 3 4))) 3))
→(store () ((lambda () (cons 3 (* 3 4)))))
→(store () (begin (cons 3 (* 3 4))))
→(store () (begin (cons 3 12)))
→(store () (cons 3 12))
→(store ((mp1 (cons 3 12))) mp1)
→(store ((mp1 (cons 3 12))) (values mp1))
くみこみかんけい
set!があるか判定する組み込み関係Vは次のように定義されます。
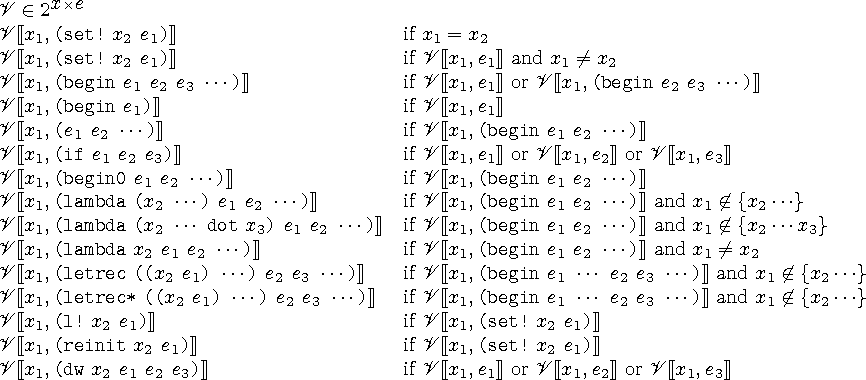
複雑な定義ですが、単に関数の中にset!があり、それが引数に対して使われているか調べるだけです。
こーるしーしーとだいなみっくうぃんど
こーるしーしー♪
かんやくきそく
call/ccとdynamic-windに関する簡約規則を見てみましょう。
dwはdynamic-windで使うもの、throwは継続オブジェクトです。
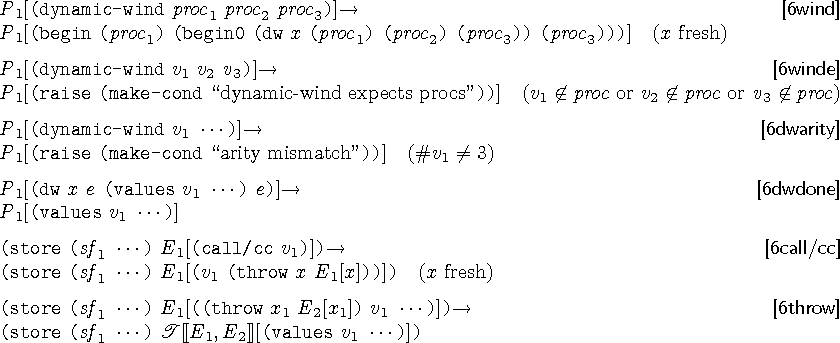
dynamic-windは引数として受け取ったサンクを順番に適用し、
2つ目の値を全体の値とします。
文脈Eの生成規則が次のようになってるため、
E ::= F[(dw x e E* e)]
(dw x e E
* e) はE
*の中だけが書き換えられ、
それが (values v...) の形式になるまで、dwそのものは残ります。
(store () (dynamic-wind + + +))
→(store () (begin (+)
(begin0 (dw x (+) (+) (+))
(+))))
→*(store () (begin0 (dw x (+) (+) (+))
(+)))
→*(store () (begin0 (dw x (+) (values 0) (+))
(+)))
→(store () (begin0 (values 0)
(+)))
call/ccは引数として受け取った引数を、
call/ccの呼び出しをユニークな識別子xで書き換えた
プログラムをthrowで包んだもの(=継続オブジェクト)に適用します。
(store () (+ (call/cc (lambda (k) (k 9))) 1))
→(store () (+ ((lambda (k) (k 9)) (throw x (+ x 1))) 1))
継続呼び出しをする際には(dynamic-windを無視すれば)
現在のプログラムを捨て、throwの中のxを引数で書き換えたものを使うだけですみます。
(store () (+ ((lambda (k) (k 9)) (throw x (+ x 1))) 1))
→(store () (+ ((throw x (+ x 1)) 9) 1))
→*(store () (+ 9 1))
実際には組み込み関数Tが返す文脈のxを(values v ...)で書き換えたものを使います。
くみこみかんすう
正しくdynamic-windを反映する継続呼び出しのための
組み込み関数T, R, Sを以下に示します。
関数Tはこれまでのプログラムと継続呼出し後のプログラムを受け取り、
これから処理すべき文脈を作り、それを返します。
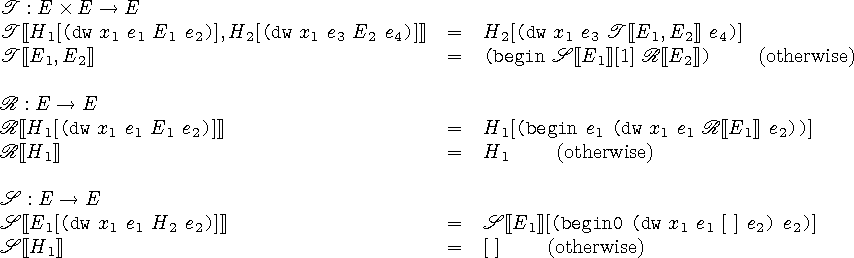
Tの1つ目の定義はあるdynamic-windの第2引数のサンクで
継続オブジェクトをつくり、
そのサンクを抜ける前に継続呼び出しをした場合です。
この場合は、そのサンク中でdynamic-windを使っているか調べます。
2つ目の定義はそれ以外の場合において、
継続呼び出しを行った時点でのプログラムの持つ
dynamic-windの第3引数(after)の適用、
その後、継続オブジェクトの保持するプログラムの持つ
dynamic-windの第1引数(before)の適用、および続きの処理を行う文脈を返します。
Rの1つ目の定義は継続オブジェクトの保持するプログラムの持つ
dynamic-windのbeforeを取り出し、
その中でさらにdynamic-windを使っているか調べます。
2つ目の定義はもうdynamic-windを使っていない場合に、
続きの処理を行う文脈を返します。
この集め方によって、外側のdynamic-windのbeforeから行うことになります。
Sの1つ目の定義は誤字ではないかと思います。
右辺のS[[E
1]]はS[[H
2]]だと私は考えます。
もし、そう仮定するとSは、
内側のdynamic-windのafterから順に呼び出すものになります。
2つめの定義より、最後のdwの要素は穴[]となるのですが、
この中にはTの定義より、1が入ります。
Sの定義は分かりにくいですが、頑張ってください。
れっとれっくとか
letrecとスタートレックって似てるわね。
エンタープライズ号がE、ベースがB、クリンゴンがCの
それぞれ1文字で表されるゲームがある方がletrecだったっけ?
めんどうなのでしょうりゃく
仕組みとしては、最初に使用する変数をメモリ上に置き、その値は
未定のもの(bh : black hole)とします。
あと、継続呼び出しにより、変数が2回初期化されないか調べるために、
そのための情報もメモリにおきます。
おわりに
現実と、戦え!
かんたんないみろんをうつしてそくいんたぷりた
簡単な意味論を写して、 即 インタプリタ♪
そんなことをできるPrologをお勧めします。
SWI-Prologのプロンプトの ?- が はてなようせい のステッキと似ていて素敵です。
(†1)何故べき集合なのか
 なんでPからRへの関数じゃなくて、PからRのべき集合へのわからない……
なんでPからRへの関数じゃなくて、PからRのべき集合へのわからない……
 入力に対する結果は一種類しかないんだから、Rへの関数でいいはずじゃ……
入力に対する結果は一種類しかないんだから、Rへの関数でいいはずじゃ……
 本当にそうかしら? 例えば実引数に (begin (set! x 0) x) みたいに代入を持つ式があったらどうなると思う?
本当にそうかしら? 例えば実引数に (begin (set! x 0) x) みたいに代入を持つ式があったらどうなると思う?
そうか、Schemeは引数の評価順序が決まってないから結果が複数ある可能性があるんだ!
ひょっとしたら無限ループになって値を持たない可能性もあるし、結果が何個あるかは分からないの
だからべき集合なんだね
(†2)穴の種類に関する注意
P[X]*と書くと、Pで使うE*やその中で使うF*で穴[]*を使うことになるの
穴の種類の情報は引き継がれるんだね
逆に、P[X] と書くと、Pで使うE*やその中で使うF*では穴[]*は使えないわ
Eの規則『 E ::= F[(handlers proc ... E*)] 』の場合がわからない……
えーと、E*は穴の種類の情報を引き継いで、あれFはどうなるんだろう?
この場合、E[X]であっても、E[X]*であっても、Fは普通の穴[]を使うことになるわ。 少し分かりにくいかな?
説明がね!